
Click to zoom
Image
Click to zoom
Image

Click to zoom
Image
Click to zoom
Image
Introduction
Netflix is not just a video streaming company; it is one of the most advanced large-scale distributed systems ever built. At any given moment, millions of users across continents press “Play” simultaneously, expecting instant startup, high-quality video, and zero interruptions. Delivering this experience requires far more than powerful servers—it demands a system designed to scale indefinitely while assuming failure is inevitable.
Netflix today serves hundreds of millions of users, operates across multiple continents, and handles petabytes of data daily. What makes Netflix’s architecture remarkable is not merely its size, but the philosophy behind it: every component is built to fail safely, recover automatically, and scale without human intervention.
This article explores Netflix’s architecture in depth—how it evolved, the problems the company faced at scale, and the architectural decisions that shaped one of the most resilient systems in the world.
From Monolith to Distributed System: Netflix’s Architectural Awakening
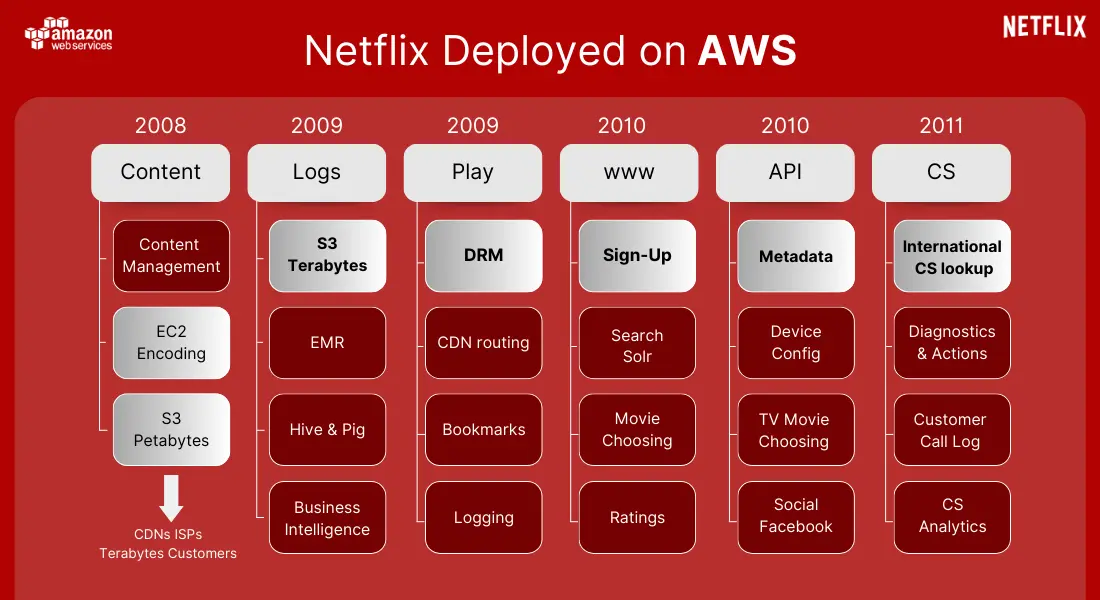
In its early years, Netflix operated like most growing tech companies. The application was largely monolithic and hosted in traditional data centers. Scaling meant purchasing hardware, provisioning servers manually, and making risky deployments during low-traffic windows.
This approach worked—until it didn’t.
In 2008, Netflix experienced a critical database failure that brought the service down for several days. The incident exposed deep structural weaknesses: tight coupling between services, limited redundancy, and an infrastructure that could not recover quickly from unexpected failures.
This outage became a defining moment. Netflix realized that reliability could not be achieved by avoiding failures. Instead, the system needed to embrace failure and continue functioning despite it.
The decision that followed was bold: Netflix would abandon its data centers entirely and rebuild its platform in the cloud.
Cloud-Native by Design on Amazon Web Services
Click to zoom
Image
Click to zoom
Image
Click to zoom
Image
Netflix chose AWS not simply as a hosting provider, but as a foundation for a new architectural mindset. The cloud allowed Netflix to treat infrastructure as code, scale resources dynamically, and distribute workloads globally.
Rather than relying on a single data center or even a single region, Netflix spread its services across multiple AWS regions and availability zones. Each service instance was designed to be ephemeral—instances could disappear at any time without causing user-visible failures.
This shift fundamentally changed how Netflix engineers built software. Servers were no longer “precious”; they were replaceable. The system’s strength came from redundancy, not individual machines.
Microservices: Breaking the Monolith Intentionally
Click to zoom
Image
Click to zoom
Image

Click to zoom
Image
As Netflix rebuilt its platform, the monolith was intentionally dismantled into hundreds of independent microservices. Each service owned a specific business capability: user profiles, recommendations, playback control, billing, search, and more.
This separation was not merely organizational—it was architectural. Services were deployed independently, scaled independently, and even failed independently.
A critical problem Netflix faced during growth was that a single failure could cascade through the system. For example, if the recommendation engine slowed down, it could impact the entire application. Microservices solved this by enforcing isolation. If recommendations were unavailable, Netflix could still stream video.
This architecture also enabled teams to move faster. Engineers could deploy changes to one service without coordinating across the entire company. At Netflix’s scale, this autonomy became essential.
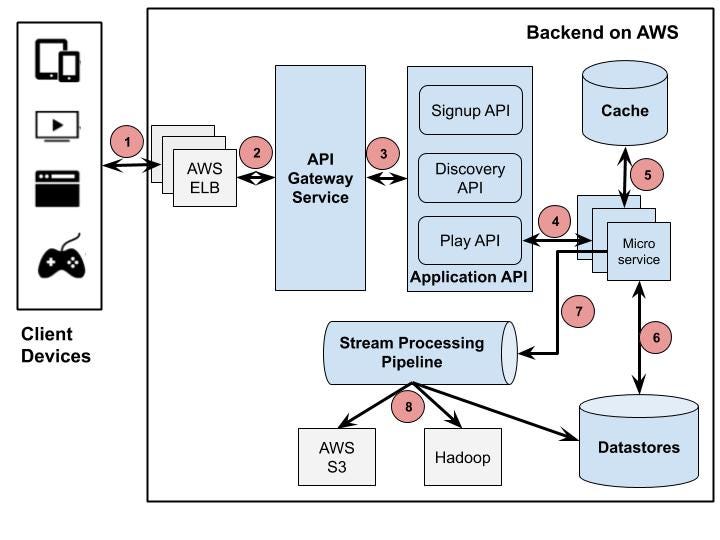
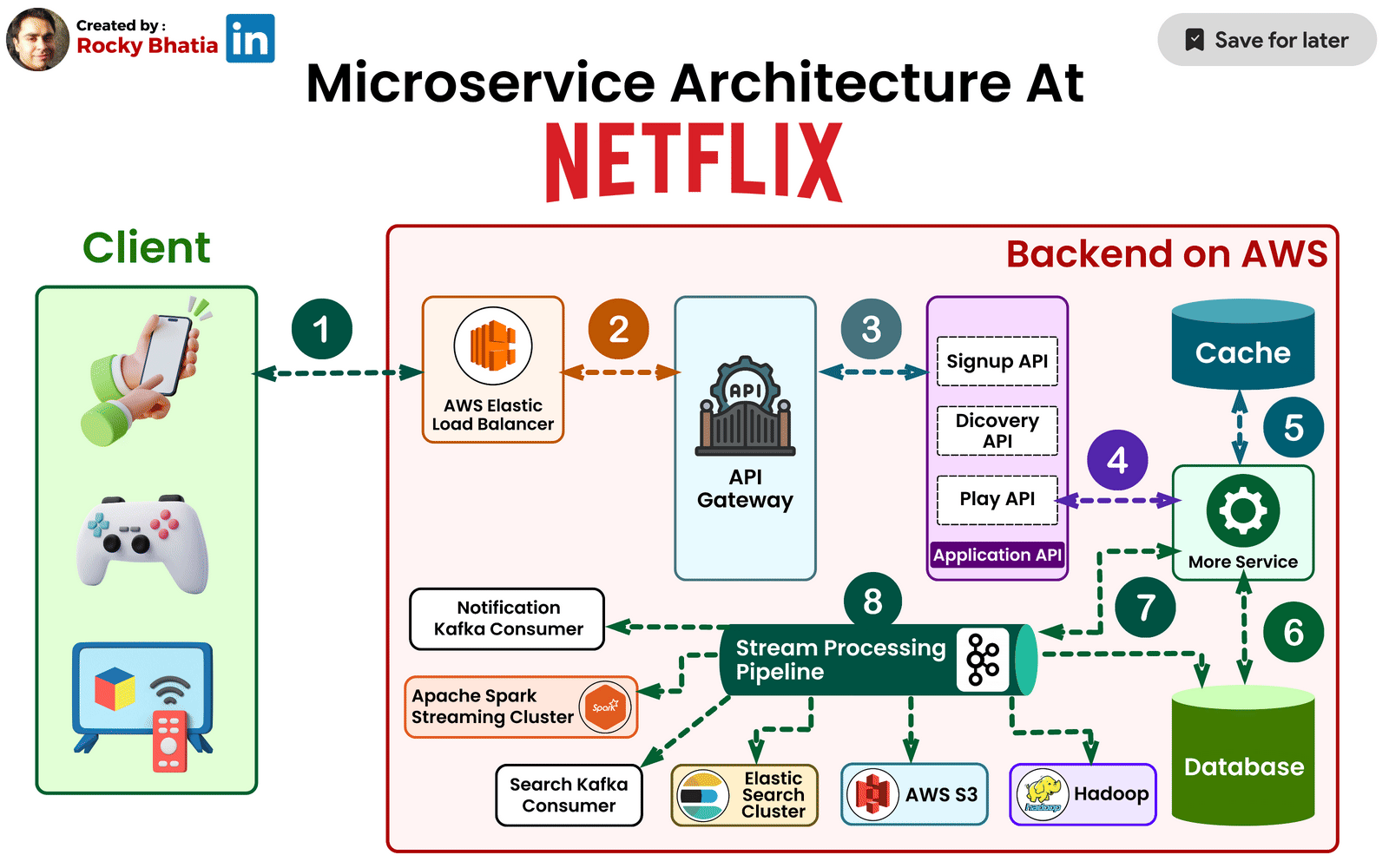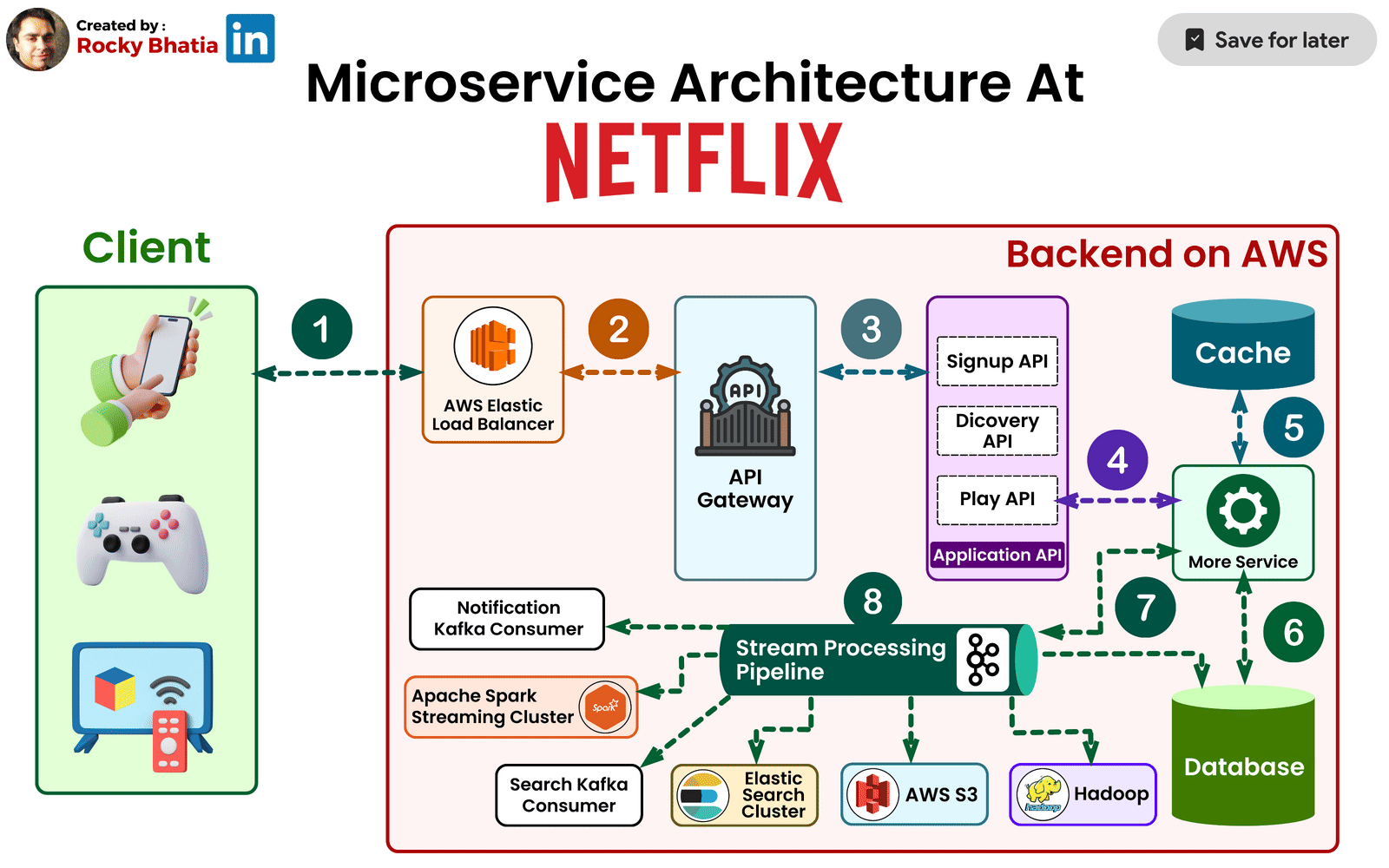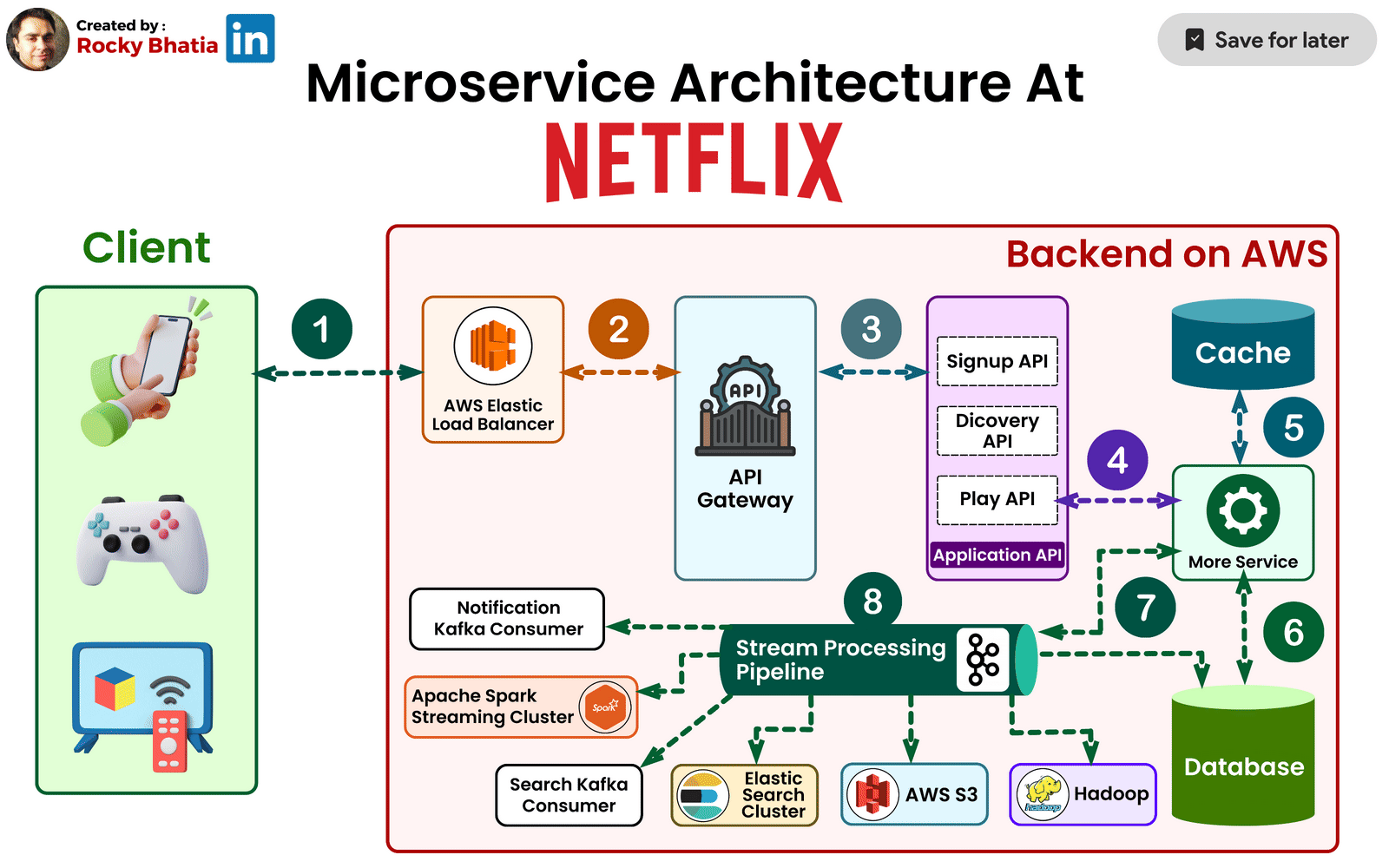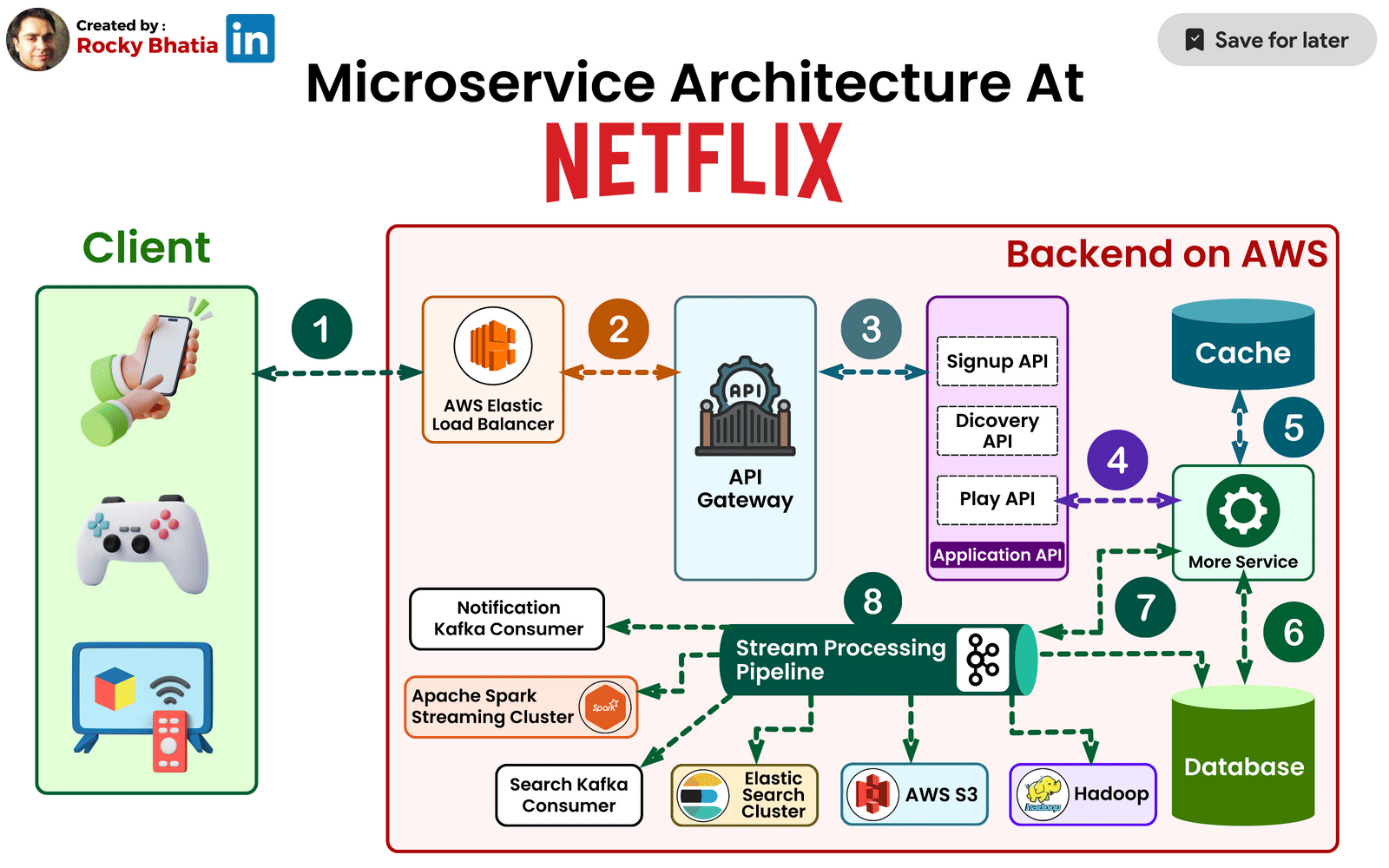
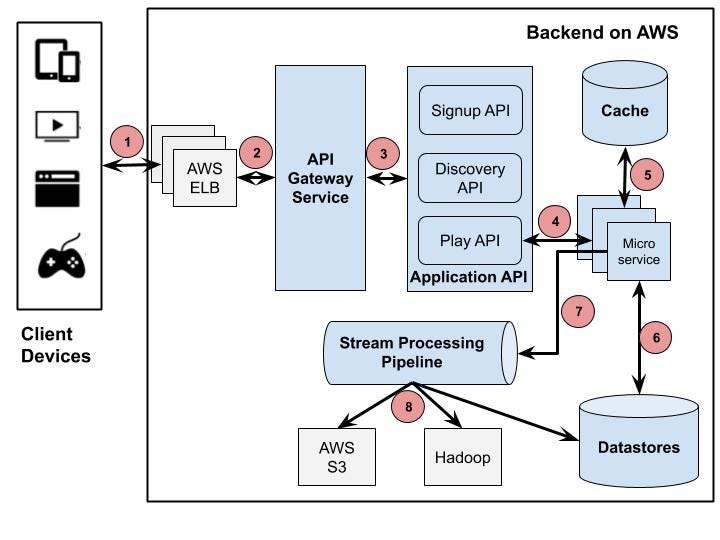
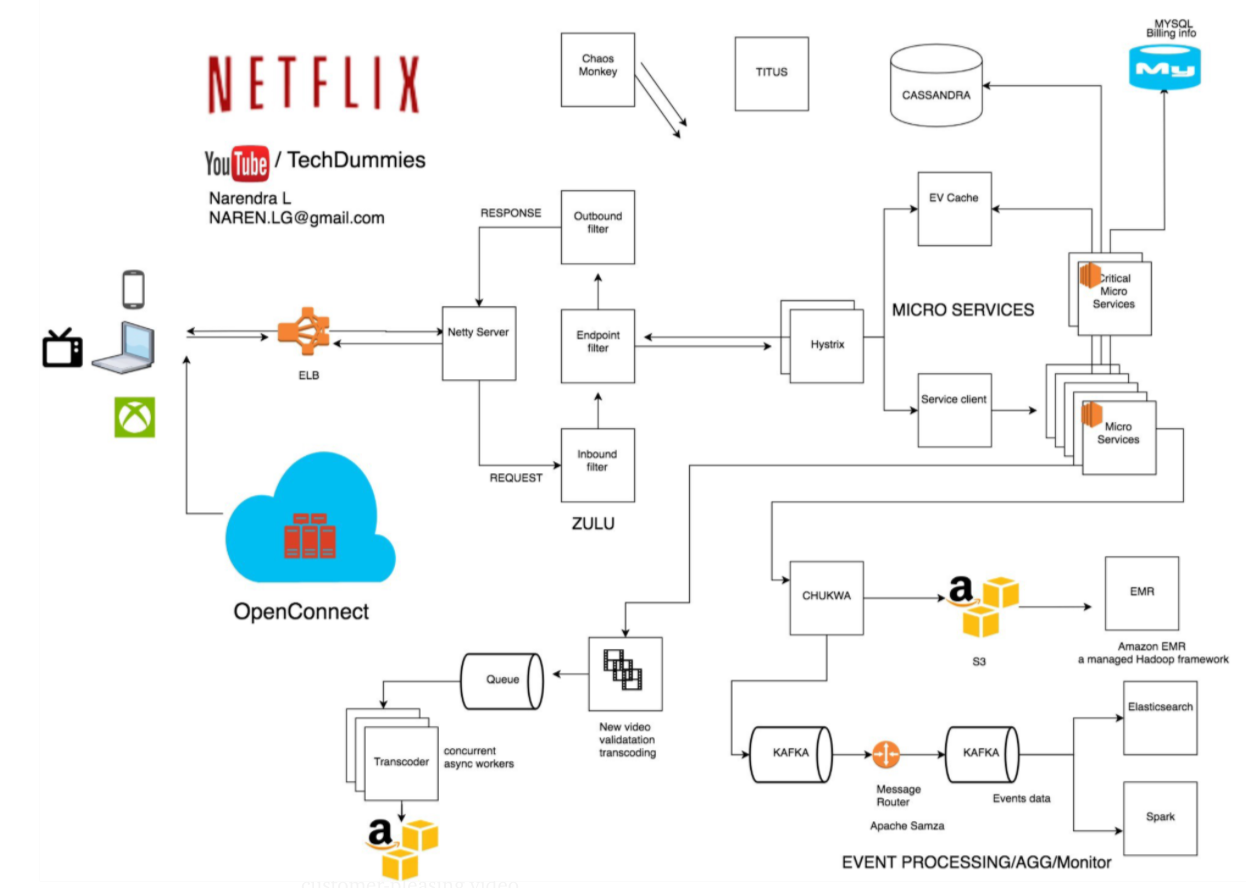
Zuul: The Intelligent Edge Layer
At the boundary between users and internal services sits Netflix’s API gateway, Zuul.
Zuul plays a crucial role in handling Netflix’s immense device diversity. Netflix runs on smart TVs, phones, tablets, gaming consoles, and browsers—each with different capabilities, network conditions, and requirements.
Zuul dynamically routes requests, applies authentication, enforces rate limits, and tailors responses based on the device making the request. This design prevents internal services from needing to understand device-specific logic, keeping backend services clean and focused.
When Netflix faced the challenge of supporting thousands of device variations, Zuul became the layer that absorbed that complexity.
Distributed Data Architecture: Scaling Without a Single Source of Truth

Click to zoom
Image
Click to zoom
Image
Click to zoom
Image
Traditional relational databases struggle under Netflix’s workload. User activity generates millions of writes per second, and data must be available across regions with minimal latency.
To solve this, Netflix adopted a distributed, multi-database strategy. Instead of a single central database, data is spread across multiple systems, each optimized for a specific access pattern.
Netflix relies heavily on Apache Cassandra, chosen for its ability to scale linearly and replicate data across regions without downtime. Cassandra stores user viewing history, personalization data, and session state—information that must always be available.
Object storage like Amazon S3 holds media assets and backups, while in-memory stores such as Redis reduce latency for frequently accessed data.
The key architectural insight here is that Netflix avoids global locks and strong consistency where possible, favoring availability and resilience instead.
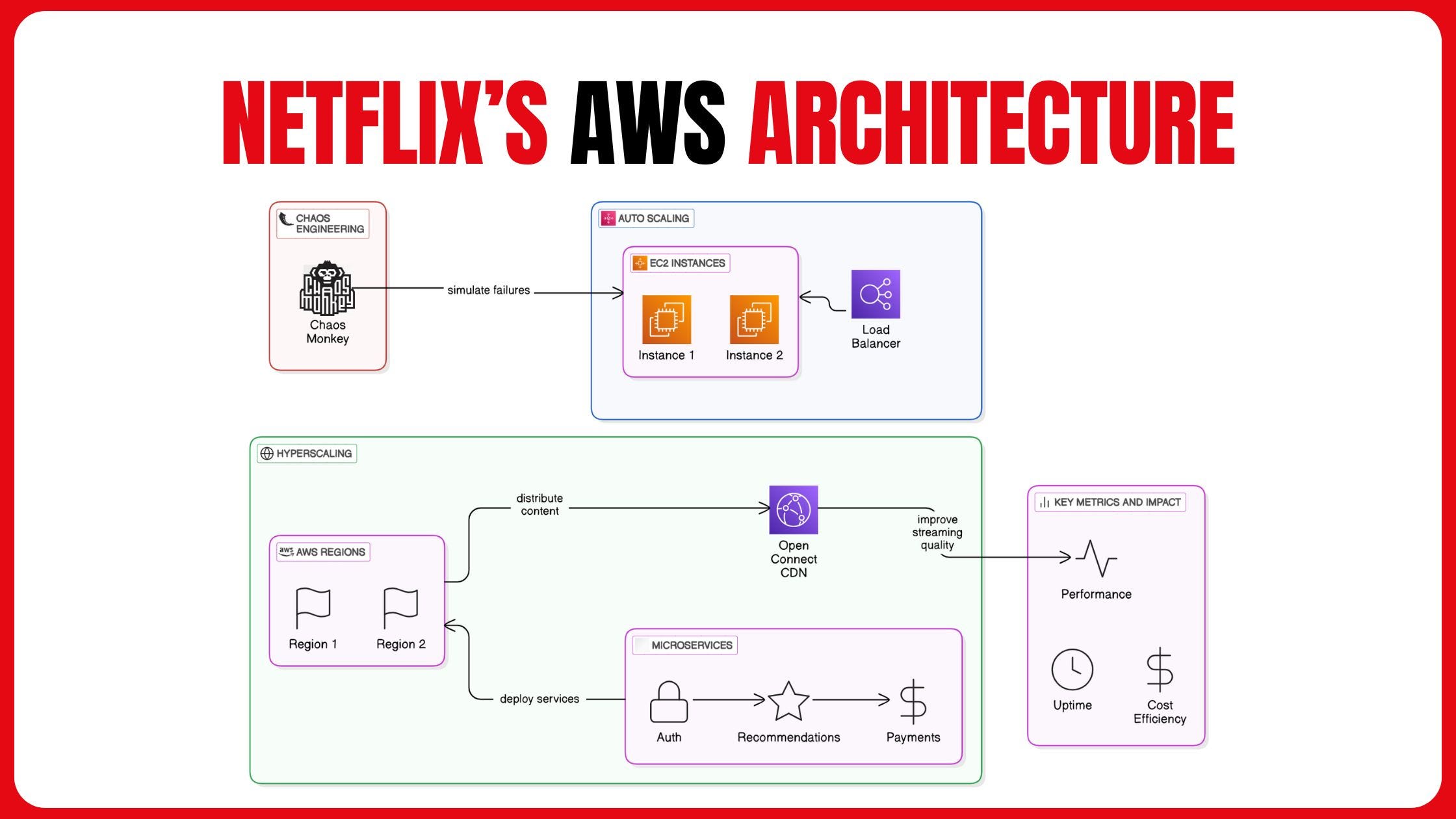
Video Delivery at Planetary Scale: Netflix Open Connect

Click to zoom
Image

Click to zoom
Image

Click to zoom
Image
Streaming video is fundamentally different from serving APIs. Bandwidth costs are enormous, and latency directly affects user experience.
Rather than relying solely on third-party CDNs, Netflix built its own content delivery network called Open Connect. Netflix deploys custom caching servers directly inside ISP networks around the world.
When a user presses play, the video is usually streamed from a server within their own ISP, drastically reducing latency and buffering while lowering transit costs for Netflix.
This approach solved one of Netflix’s biggest scaling challenges: delivering massive volumes of data reliably across the globe without depending entirely on external providers.
Designing for Failure: Chaos Engineering

Click to zoom
Image

Click to zoom
Image
Click to zoom
Image
Netflix operates under a simple assumption: everything will eventually fail.
To ensure the system can survive real outages, Netflix pioneered chaos engineering. Tools like Chaos Monkey randomly terminate production instances during business hours.
This forced engineers to design systems that could withstand failures automatically. Over time, Netflix expanded this approach to simulate entire region failures, network latency, and dependency outages.
The result is a platform that is continuously tested against disaster scenarios—long before users ever experience them.
Observability and Continuous Delivery at Extreme Scale
Netflix deploys changes thousands of times per day. This velocity is only possible because of deep observability and automated deployment pipelines.
Custom-built systems monitor everything from request latency to playback success rates. Canary deployments ensure that new changes are tested on small user subsets before global rollout. If anomalies are detected, rollbacks happen automatically.
At Netflix’s scale, manual intervention is a liability. Automation is the only way to move fast without sacrificing reliability.
Architectural Lessons from Netflix
Netflix’s architecture teaches lessons that apply far beyond streaming:
- Scalability comes from distribution, not bigger machines
- Reliability is achieved by expecting failure, not avoiding it
- Microservices succeed only with strong automation and observability
- Global systems must optimize for latency and locality
- Culture and architecture evolve together
Conclusion
Netflix’s scalable architecture is the result of years of iteration, failures, and relentless engineering discipline. There is no single “Netflix stack” to copy—but the principles behind it are universal.
By embracing the cloud, decentralization, failure testing, and automation, Netflix built a system capable of serving the world—one play button at a time.
